Karhunen-Love Digits 64-Dimensions¶
Pipeline description¶
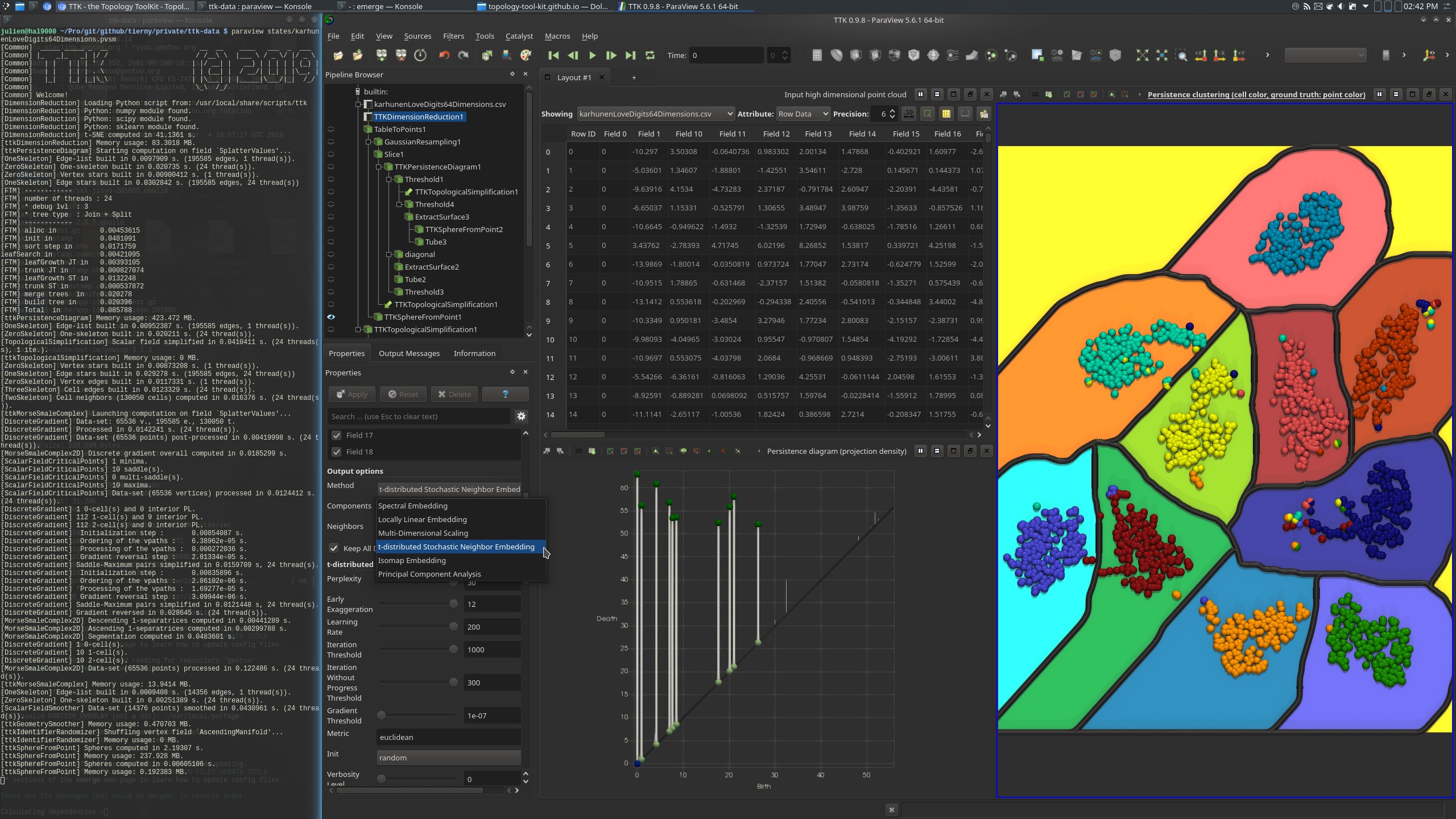
This example performs a persistence driven clustering of a high-dimensional data set, specifically a collection of 2000 images representing hand written digits. Each image is encoded by its Karhunen-Love coefficients, a 64-dimensional vector. This results in a point cloud of 2000 points (2000 rows), living in 64 dimensions (64 columns).
The ground truth classification for each point is provided by the column Field0 (point color in the bottom right view, above screenshot), which indicates the digit represented by the corresponding image.
The pipeline starts by using DimensionReduction (with tSNE) to project the data down to 2D.
Next, the density of the projected 2D point cloud is estimated with a Gaussian kernel, by the GaussianResampling filter, coupled with the Slice filter (to restrict the estimation to a 2D plane).
Next, the PersistenceDiagram of the density field is computed and only the 10 most persistent density maxima are selected (corresponding to the 10 classes, one per digit, bottom left view in the above screenshot).
Next, the simplified persistence diagram is used as a constraint for the TopologicalSimplification of the density field. The simplified density field then contains only 10 maxima and it is used as an input to the Morse-Smale complex computation, for the separation of the 2D space into the output clusters (background color in the bottom right view, above screenshot).
Finally, the cluster identifier of each input point is given by the identifier of the
corresponding ascending manifold of the Morse-Smale complex (AscendingManifold), with the ResampleWithDataset filter.
ParaView¶
To reproduce the above screenshot, go to your ttk-data directory and enter the following command:
paraview states/karhunenLoveDigits64Dimensions.pvsm
Python code¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 | |
To run the above Python script, go to your ttk-data directory and enter the following command:
pvpython python/karhunenLoveDigits64Dimensions.py
Inputs¶
- karhunenLoveDigits64Dimensions.csv: an input high dimensional point cloud (2000 points in 64 dimensions).
Outputs¶
OutputClustering.csv: the output clustering of the input point cloud (output cluster identifier:AscendingManifoldcolumn, ground truth:Field0)